Reverse cache(反向cache)
面对微博常常出现的热点,如最近出现了较为火爆的短链,短时间有数以万计的人点击、跳转,而这里会常常涌现一些需求,比如我们向快速在跳转时判定用户等级,是否有一些账号绑定,性别爱好什么的,已给其展示不同的内容或者信息。
普通采用memcache+Mysql的解决方案,当调用id合法的情况下,可支撑较大的吞吐。但当调用id不可控,有较多垃圾用户调用时,由于memcache未有命中,会大量的穿透至Mysql服务器,瞬间造成连接数疯长,整体吞吐量降低,响应时间变慢。
这里我们可以用redis记录全量的用户判定信息,如string key:uid int:type,做一次反向的cache,当用户在redis快速获取自己等级等信息后,再去Mc+Mysql层去获取全量信息。如图:
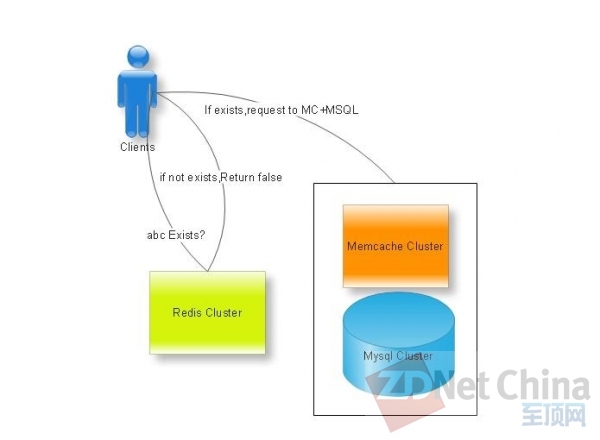
当然这也不是最优化的场景,如用Redis做bloomfilter,可能更加省用内存。